Background: Cancer survivors often experience complex and coexisting emotions throughout diagnosis, treatment, and posttreatment life. Emotion classification of patient narratives may help in understanding survivorship experiences; however, evidence remains limited for multidimensional classification using cancer survivor interview narratives. Objective: This study aimed to develop and evaluate natural language processing–based emotion classification models using Japanese cancer survivor interview narratives and to examine whether polarity and multidimensional emotion labels provide complementary perspectives. Methods: We analyzed verbatim transcripts from 15 cancer survivor interviews published by the Cancer Note, Nonprofit Organization. Survivor utterances were extracted, noninformative conversational elements were removed, texts were segmented at Japanese punctuation marks, and 5 consecutive sentences were grouped into 1 chunk. Two annotators labeled 1998 text chunks with 3-class sentiment polarity labels (positive, neutral, or negative) and multilabel Plutchik 8-emotion labels (joy, trust, fear, surprise, sadness, disgust, anger, and anticipation). Japanese BERT (Bidirectional Encoder Representations from Transformers) and LUKE (Language Understanding with Knowledge-based Embeddings) were fine-tuned to build a multiclass polarity classifier and a multilabel 8-emotion classifier. Performance was evaluated using precision, recall, -score, macroaveraged metrics, Micro- for polarity, and Hamming loss for multilabel classification. For comparison, the same architectures were fine-tuned on WRIME (writers’ and readers’ intensities of emotion for their estimation), a Japanese social media emotion dataset, and evaluated on Cancer Note texts as a domain-transfer analysis. The 95% CIs were estimated using bootstrap resampling with 1000 iterations. Results: Neutral was the most frequent polarity label, trust was the most frequent 8-emotion label, and anger was the least frequent emotion label. Label distributions were imbalanced, with most-to-least frequency ratios of 3.47 for polarity and 8.10 for 8-emotion labels. In the 3-class sentiment polarity task, interview-trained models outperformed WRIME-trained transfer models. Interview Text-BERT achieved the highest micro- of 0.696 (95% CI 0.676‐0.716), whereas Interview Text-LUKE achieved the highest macro- of 0.660 (95% CI 0.639‐0.682). In the 8-emotion multilabel task, Interview Text-LUKE achieved the highest macro- of 0.427 (95% CI 0.398‐0.453) and the lowest Hamming loss of 0.078 (95% CI 0.073‐0.082). WRIME-trained transfer models showed lower performance, particularly in the 8-emotion task. Sadness and trust co-occurred most frequently, suggesting that positive and negative emotional elements may coexist in the same narratives. Conclusions: This exploratory study suggests the feasibility of domain-specific emotion classification for Japanese cancer survivor interview narratives. Models fine-tuned on target-domain narratives generally outperformed WRIME-trained transfer models, although the best architecture differed by task and metric. Polarity labels and Plutchik 8-emotion labels provided complementary perspectives on complex and coexisting emotions in survivorship narratives. However, performance for rare emotions remained limited, and the models should be regarded as preliminary research tools rather than clinically actionable systems. Larger, more diverse, prospectively or externally validated datasets, imbalance-aware methods, and user-centered evaluation are needed before clinical translation.
<img src="https://jmir-production.s3.us-east-2.amazonaws.com/thumbs/c55302eeaf28f695d0c405aa15e4c529" />
New Agentic Capabilities for Tasks Across the Complete Research Workflow
Officials at Elsevier say the company is expanding LeapSpace, a research-grade AI workspace, with new agentic capabilities that help “researchers carry out an even greater range of tasks within their complex workflow to drive better outcomes with confidence.”
Designed specifically for the end-to-end research workflow, LeapSpace was created to accelerate discovery, help researchers calibrate the strength of the evidence, and support critical thinking. LeapSpace draws on 20+ million full-text peer-reviewed articles and books from Elsevier and over 1,000 new content licensing partners, including Sage Publishing, Emerald Publishing, IOP Publishing, and NEJM Group. as well as 100+ million scientific records from 7,000+ publishers on Scopus.
Results are grounded in peer-reviewed literature, citations are traceable to sources, Trust Cards help researchers calibrate the strength of evidence, and the researcher remains in control, with every recommended change requiring approval, notes an Elsevier spokesperson.
General-purpose AI tools can generate text, summarize articles and automate some tasks. But researchers require something more demanding: the latest trusted peer-reviewed content, verifiable citations, transparent reasoning, research integrity safeguards, and enterprise-grade security and privacy, according to Stuart Whayman, president, corporate markets, Elsevier, adding that this is what LeapSpace is built for.
Built with research-grade AI, LeapSpace is already delivering results for thousands of researchers around the world: 97% report time savings, with more than half saving over 50% of their research time, points out Whayman, LeapSpace is now extending support to writing—the task researchers most want AI to help with: more than half find writing clearly and concisely to convey complex ideas a challenge, rising to 60% among students and early-career researchers.
The post New Agentic Capabilities for Tasks Across the Complete Research Workflow appeared first on GEN – Genetic Engineering and Biotechnology News.
Midlands trust launches digital medicines management system
University Hospitals Coventry and Warwickshire (UHCW) NHS Trust has gone live with an interoperable digital medicines management system.
High Intensity Training for Adults With ADHD in Specialised Mental Health Care
Conditions: Attention Deficit Disorder With Hyperactivity (ADHD)
Interventions: Behavioral: High intensity training
Sponsors: Solli Distriktspsykiatriske Senter; Helse Bergen Hospital Trust
Enrolling by invitation
Interventions: Behavioral: High intensity training
Sponsors: Solli Distriktspsykiatriske Senter; Helse Bergen Hospital Trust
Enrolling by invitation
Agent confidence on the technical frontier
Enterprise investment in AI is booming. Gartner is calling 2026 an “inflection year” for organizations to align their AI projects with strategic business objectives. As the pressure to prove ROI mounts, executives and technology leaders are looking to agentic AI to drive the measurable financial outcomes their businesses seek.
A prime opportunity for AI agents exists in the tech function, where IT infrastructure costs are projected to grow two to three times by 2030, even as budgets remain unchanged, according to McKinsey. And in the last 18 months, tech teams—the engineers, developers, architects, and other practitioners who are building, deploying, and continually improving their organizations’ infrastructure and applications—are clearly putting agents to work.

The ultimate promise of agents is not only to automate tasks but to manage and coordinate entire workflows, pursuing business goals in a way that allows humans and agents to work together. Given the risks involved in automated decision-making, teams cannot delegate the work that agents do without confidence that they are fully capable of performing the task and that it will do so in a safe, reliable, and secure manner.
Among technology experts, our research shows that teams are exceedingly confident about using agentic AI across a significant amount of AI, data, and cloud tasks.

Where agent readiness drops is largely due to a lack of business context being supplied to agentic systems. The more complex the task, the more reasoning capability an agent requires and the greater its need for business context. Such context-generation capabilities for agents are still at an early stage of development, especially in situations where enterprise data is difficult to wrangle and connect into the agent lifecycle at the speed and quality in which developers and executives need it. Human oversight is a key factor of success in deploying agentic AI.
Knowing that tech teams are in a pivotal position to lead this transformation, the experts we interviewed expect agent confidence to accelerate as experience with agents deepens and business environments mature. “As we design agents to operate within the same operational boundaries, identity systems, and governance models that teams already use, they start to behave more like the systems organizations already trust,” says Jeremy Winter, corporate vice president and chief product officer at Microsoft Azure Platform.
This report, based on a survey of 300 global technology experts, ranks 101 tasks across AI, data, and cloud workflows based on respondents’ confidence in agents acting on their behalf. It also examines how technology teams view the opportunities and challenges related to agentic AI, along with the potential for the technology to enhance their careers.
Key findings from the report include:
Confidence in agents is surging for measurable tasks and growing in areas of complex judgment. Technology experts overwhelmingly believe agents help with everyday work including streamlining processes, improving performance, and reducing repetitive tasks. Confidence is highest for processes like generating reports and boilerplate code, and there is clear opportunity where tasks involve multistep workflows and advanced reasoning to make decisions.
Data workflows are the breakthrough domain. Tech teams trust agents most where structure can provide a reliable foundation for decisions. This includes areas such as data quality monitoring, visualization anomaly detection, real-time data stream monitoring, and data profiling. This is where domain experts closest to the point of data generation can provide context to allow agents to act and deliver trusted outcomes.
Read the Microsoft Cloud blog by Amanda Silver, corporate vice president of Microsoft 365 Core and Work IQ, which underscores the importance of keeping humans in the loop and how systems thinking advances careers. And for a deeper dive into data workflows as a breakthrough use case for agents, check out the Fabric blog to hear from Kim Manis, corporate vice president of Product for Microsoft Fabric.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
The Download: metric weaknesses and AI elephant warnings
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The inevitable weakness of metrics
There are plenty of useful things a metric can reveal. There are even more that it can obscure or corrupt.
Like a lot of people bitten by the self-quantifying bug, I started gathering personal data to pursue a nebulous collection of goals and desires. I wanted to feel better physically and emotionally, get outside more, and bring order to the messiness and uncertainty of my daily existence.
But external metrics and data can never capture what’s truly important. Worse, they inevitably redefine your core sense of what’s important, whether you’re aware of the trap or not.
Dive into the dangers of quantifying our lives with metrics.
—Bryan Gardiner
This story is from the next edition of our magazine, which is all about engineering. Subscribe now to get a copy when it lands!
Elephant alert! AI warning systems aim to avoid deadly clashes
India is home to about 60% of the world’s wild Asian elephants, and around 80% of their habitat lies outside protected areas. That brings them into close contact with people, and clashes can turn lethal: there have been some 3,000 human casualties in the last five years and over 1,000 elephant deaths since 2014.
In response, state forest departments, NGOs, and locals are designing, testing, and deploying a range of AI systems that cut response and warning times to minutes—or even seconds. They range from wildlife eyes in Maharashtra to infrared drones in Chhattisgarh.
Find out how they work in our interactive map.
—Kanika Gupta
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 The US has allowed Anthropic to release Mythos 5 to “trusted” orgs
About 100 US companies and federal agencies now have access. (Semafor)
+ The White House said appropriate safeguards were now in place. (WSJ $)
+ The US had restricted both models over national security concerns. (BBC)
+ Which raised new questions about AI safety. (MIT Technology Review)
2 A Chinese AI model has matched Mythos in finding security bugs
Security researchers say Zhipu AI is poised to reset the AI race. (WSJ $)
+ It’s sparked alarm that US restrictions are boosting China’s progress. (NYT $)
+ Although it still can’t match Anthropic or OpenAI on general tasks. (Verge)
+ In the AI race, China is eyeing a come-from-behind victory. (WP $)
3 Apple is seeking approval to buy chips from a blacklisted Chinese firm
It’s lobbying the White House for clearance to buy from ChangXin. (FT $)
+ ChangXin is on a Pentagon list of firms with Chinese military ties. (WP $)
+ Chipmakers are profiting off AI at the expense of everyone else. (WSJ $)
+ The US is banning imports of more Chinese technology. (Reuters $)
+ But Chinese tech companies feel optimistic. (MIT Technology Review)
4. South Korea plans to train its entire military as “drone warriors”
It wants to train all 500,000 personnel. (Reuters $)
+ And produce 110,000 drones by 2029. (Ars Technica)
5 Google has limited Meta’s use of its Gemini AI models
Meta wanted more compute than Google could provide. (FT $)
+ The cap has disrupted and delayed some Meta AI projects. (Bloomberg $)
6 Zuckerberg wants Meta to work with Polymarket and Kalshi
Meta wants its own prediction market, but without real-money bets. (NYT $)
+ The partnerships could hedge risks and accelerate development. (Reuters $)
7 Extreme heat is putting already hot data centers under pressure
Severe weather is now the leading cause of loss for data centers. (CNBC)
+ Heat waves also mess with your brain. (MIT Technology Review)
8 Android phones alerted millions moments before Venezuela’s earthquakes
They gave users between seconds and up to two minutes’ notice. (NYT $)
9 Scientists think Uranus and Neptune may not be the icy giants we imagined
They may have a magma ocean brewing on the inside. (Gizmodo)
10 Too much sleep may be as harmful as too little
A new study suggests 6.4–7.8 hours is the sweet spot. (Economist $)
Quote of the day
“This kind of powerful weapon that can alter the landscape of cyberwarfare can’t remain solely in American hands.”
—360 Security CEO Zhou Hongyi tells a cybersecurity conference in Beijing why Chinese AI firms need to match the capabilities of their rivals in the US, The Wall Street Journal reports.
One More Thing

GETTY
Why Generation Z falls for online misinformation
Research shows that young people are more likely to believe and pass on misinformation if they feel a sense of common identity with the person who shared it in the first place.
Offline, teenagers are likely to draw on the context that their communities provide. Social media, however, promotes credibility based on identity rather than community. And when trust is built on identity, authority shifts to influencers.
As young people participate in more political discussions online, those who have successfully cultivated identity-based credibility could become de facto community leaders, attracting like-minded people and steering the conversation. While that has the potential to empower marginalized groups, it also exacerbates the threat of misinformation.
Find out what we can all learn about how young people evaluate truth online.
—Jennifer Neda John
We can still have nice things
A place for comfort, fun, and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ The Euclid space telescope has captured the most detailed image yet of the Milky Way.
+ Here’s a lovely, lilting medieval bardcore cover of Daft Punk’s electronic classic Veridis Quo.
+ A toilet plunger becomes an unlikely engineering breakthrough in this quest to build a better blowgun.
Opinion: Banning gender-affirming care doesn’t protect children — it makes it harder to help them
I am a plastic surgeon who rebuilds faces after car accidents, helps cancer patients breathe, and restores infants’ ability to eat and smile. Yet what draws the most notice is my work transforming masculine features into feminine ones, and vice versa.
I am an outsider to the LGBTQIA+ community. I grew up in a conservative household in which discussions on sex and gender were taboo. But in residency, I saw patients in clinic every Monday with my attending, a cisgender, white, heterosexual male at least 60 years old, who had been providing surgical gender-affirming care for over 25 years. I saw how vulnerable the patients were, trapped in their bodies. I felt the weight they woke up with every day, trying to blend into the surrounding world of instantaneous judgements. And I saw the life-changing impact that surgery had.
Implementing a Commercial AI Fracture Detection Tool in Health Care Using the Non-Adoption, Abandonment, Scale-Up, Spread, and Sustainability Framework: A Formative Evaluation Study
Background: Artificial intelligence (AI) has the potential to enhance resource efficiency, improve patient treatment, and increase safety in health care. Still, there is limited knowledge on how to implement and evaluate AI solutions in real-world clinical settings. To address this gap, we conducted a formative process evaluation of the first large-scale procurement and implementation of a commercial AI solution in Norwegian health care. F The Non-Adoption, Abandonment, Scale-up, Spread, and Sustainability (NASSS) framework, was used for the formative process evaluation throughout the 4-year project to guide data collection, analysis, and real-time feedback. Objective: This study aimed to evaluate the usefulness of the NASSS framework for formative process evaluation of AI implementation in health care. Methods: A formative process evaluation was conducted from 2020 to 2024, covering the procurement, preimplementation, and implementation phases. Data included 65 interviews, observations, and document analysis. Data were analyzed thematically using the 7 NASSS domains, supplemented with subtopics within each domain to capture emerging infrastructural complexities and temporal dynamics. Real-time findings were discussed with the implementation team, decision-makers, and clinicians. Results: Key factors for successful implementation included clinician trust, workflow integration, task distribution, and digital maturity. Major challenges comprised limited documentation of Conformité Européenne–marked solutions, deskilling, and misaligned financial incentives. The NASSS framework enabled the identification of sociotechnical values and complexities, but did not fully capture workflow evolution and changing user perceptions over time. Conclusions: The NASSS framework is useful for evaluating AI implementation but requires adaptation to capture temporal dynamics and workflow changes better. These findings contribute to improving evaluation approaches for AI in health care.
<img src="https://jmir-production.s3.us-east-2.amazonaws.com/thumbs/b9322988a1331e55bc3e6cfe83e31278" />
Frimley Health achieves HIMSS EMRAM Stage 6
Frimley Health NHS Foundation Trust has become one of only seven NHS organisations in the UK to achieve HIMSS EMRAM Stage 6 accreditation.
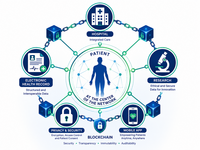
Patient Perceptions and Acceptance of Blockchain-Based Health Data Sharing in Oncology: Cross-Sectional Survey
Background: Fragmentation of electronic health records in oncology hinders coordinated care, delays diagnoses, and limits therapeutic personalization. Blockchains promise to promote secure, interoperable, and patient-centered data governance; however, patient perceptions of blockchains remain underexplored, particularly in middle-income countries such as Brazil. Objective: We assessed opinions, attitudes, and willingness among patients with cancer to digitally share clinical information and the feasibility of applying blockchains to restructuring secure health data sharing in the Brazilian public health context. We had three research questions: (1) What is the level of digital health tool acceptance among patients with cancer in Brazil? (2) Which sociodemographic factors are associated with willingness to share health data? (3) Are blockchains feasible and acceptable for restructuring secure oncology data sharing? Methods: An exploratory, descriptive, cross-sectional self-report survey was conducted at Hospital Santa Izabel, a national oncology reference center in Salvador, Bahia, Brazil, between September and November 2023. A convenience sample of 110 outpatients with cancer was recruited systematically; data were collected via a self-administered questionnaire. The 20-item instrument, developed de novo and validated via expert panel and pilot testing, covered 5 content domains yielding 3 composite scoring domains: self-management, adherence, and governance. We used Cronbach α to assess internal consistency, independent 2-tailed tests, 1-way ANOVA, and Pearson correlations to compare domain scores across sociodemographic groups, and a chi-square goodness-of-fit test to examine trust proportions across recipient types. Results: We received sufficiently complete responses from 94.5% (104/110) of patients. The sample was predominantly female (63/98, 64.3%), self-identified as (mixed-race; 64/98, 65.3%), and lower income (55/96, 57.3% earned less than twice the minimum wage). Acceptance of technology was high: 86.4% (95/110) would use health apps and 89.1% (98/110) expressed interest in prevention-focused applications. Trust in data sharing varied significantly across recipient types (=210.4; <.001): 79.1% (87/110) trusted health care professionals, 51.8% (57/110) hospitals, 15.5% (17/110) the pharmaceutical industry, and 10% (11/110) the government. Anonymization and encryption significantly increased willingness to share (92/110, 83.6%). Younger patients (18‐59 years) showed significantly higher adherence scores than those aged ≥60 years (mean 76.49, SD 19.16 vs mean 65.83, SD 26.66; =2.29; =.02). Domain reliability was good to excellent (Cronbach α=0.8807 [adherence], 0.8504 [self-management], and 0.7576 [governance]). Conclusions: Patients with cancer in Brazil demonstrated high acceptance of digital health tools and openness to data sharing when privacy, security, and governance are guaranteed. This supports the feasibility of blockchain-based health data management systems, provided they incorporate patient-centered principles, digital inclusion strategies, and robust governance aligned with Brazilian regulations (the General Data Protection Law) and the Unified Health System (Sistema Único de Saúde) infrastructure. Importantly, patient support reflected acceptance of blockchain’s functional principles, data security, anonymization, and auditability rather than familiarity with the technology itself, a distinction with direct implications for future implementation studies. International Registered Report Identifier (IRRID): RR2-10.2196/89278