
Background: Enterovirus infections cause substantial pediatric morbidity worldwide, with severe cases requiring hospitalization. Accurate forecasting of hospitalization burden supports proactive resource allocation and clinical preparedness. During the postpandemic period (2023‐2024), Taiwan experienced a resurgence of enterovirus activity following COVID-19–related suppression, although at levels below prepandemic baselines, creating unique operational forecasting challenges. Objective: This study aimed to develop and validate random forest models for 1-week-ahead enterovirus hospitalization forecasting using postpandemic surveillance data and to evaluate the impact of epidemiological regime alignment on predictive performance. Methods: We analyzed weekly enterovirus surveillance data from Taiwan’s Centers for Disease Control covering 2023 to 2024, including outpatient, emergency department, and hospitalization counts stratified by five age groups (0‐2, 3‐4, 5‐9, 10‐14, and ≥15 y). Random forest models were trained on data from 2023 week 1 to 2024 week 40 (n=91 wk after lag preprocessing) and validated on a temporally independent test set covering 2024 weeks 41 to 52 (n=11 wk). Feature engineering incorporated age-specific indicators, 1‐ to 4-week temporal lags, seasonal variables, and derived epidemiological ratios. Results: The random forest model achieved strong 1-week-ahead forecasting performance on the test set (²=0.216, root mean square error 23.5 hospitalizations per week, mean absolute percentage error 17.27%). Age-specific outpatient visits among children aged 0 to 2 and 3 to 4 years were the most influential predictors (feature importance=0.0839 and 0.0908, respectively), followed by seasonal week-of-year effects (feature importance=0.0803). The mean absolute error was 17.6 hospitalizations per week, demonstrating practical utility for hospital capacity planning. Test-period hospitalizations averaged 126.5 cases per week, representing a 3.4-fold increase from pandemic suppression levels (28.4 cases per week during 2020‐2022) while remaining 24% below prepandemic baselines (165 cases per week during 2008‐2019). Conclusions: Machine learning models trained on recent postpandemic surveillance data provide useful short-term forecasts of enterovirus hospitalization burden in Taiwan. A mean absolute percentage error of 17.27% represents reasonable accuracy for 1-week-ahead hospital resource planning. Age-specific pediatric outpatient surveillance offers valuable early signals for hospitalization forecasting, supporting the integration of such models into routine public health practice during postpandemic recovery.
<img src="https://jmir-production.s3.us-east-2.amazonaws.com/thumbs/4b565965def619d0610c3371f9fb9396" />
Clinical trial set to test two drugs for fast-growing Ebola outbreak
A clinical trial testing two drugs against the Bundibugyo ebolavirus, which is driving a fast-moving outbreak in Central Africa, is set to begin next week, World Health Organization officials said Wednesday.
The clinical trial — which will test both Gilead Sciences’ antiviral drug remdesivir and MappBio’s monoclonal antibody MBP-134 — will be conducted in the Democratic Republic of the Congo. The trial is designed to test whether either of the therapies is effective against this form of Ebola, and whether using the two in combination would be a more effective way to combat the disease.
Medical AI Model Privacy Risks
Research led by the Technical University of Munich shows that data from some individuals used to train medical artificial intelligence (AI) models could be at much higher risk of exposure due to cyberattack than others.
Writing in Nature, the researchers explain that underrepresented groups, such as people with a rare disease or a minority ethnicity, are at particularly high risk of having their data exposed.
A type of cyberattack called a “membership inference attack” can be used to uncover sensitive information about individuals or learn about the training data behind an AI system, without seeing the original database. In the wrong hands, this kind of information can be used for discrimination, blackmail, or even to assess who might be vulnerable to exploitative marketing.
“The extent to which this constitutes a privacy violation is nuanced and depends on factors such as the underlying training population and the deployment context of the model. Although inferring membership for a model trained on a general population may be benign, doing so for a model trained on a narrow, disease- or center-specific cohort acts as a direct proxy for sensitive medical information,” explained lead author Moritz Knolle, a doctoral researcher at the Technical University of Munich, and colleagues.
In this study, the team studied seven large, real‑world clinical datasets including medical images, electrocardiograms, and electronic health records. They trained around 200 versions of an AI model for each dataset, then quantified, for every single record and patient, how accurately an attack would be at guessing if a patient was part of the training set.
They showed that membership inference attacks can be almost perfectly successful for some individual patients, such as those with an unusual disease or presentation, even though the average attack performance across the whole training set looked close to random guessing.
As the AI model capacity increased, the number of highly vulnerable patients rose substantially. Underrepresented groups in the training group, for example, by disease, ethnicity, insurance, sex, or imaging protocol, were among the most vulnerable records to this kind of attack.
Current practice tends to check the privacy vulnerability of AI models by taking an average from the whole dataset. “Together, our findings show that aggregate privacy metrics can severely underestimate individual privacy risk,” warned Knolle and colleagues.
“Given this vulnerability, medical AI models and their deployment contexts should be assessed for the sensitive information that attackers could obtain by successfully inferring training dataset membership. To prevent privacy harm, we recommend that vulnerable models be protected by verifiable risk mitigation strategies and/or strict access controls.”
The post Medical AI Model Privacy Risks appeared first on Inside Precision Medicine.
Novel Feeder Cell Line Dramatically Expands NK Cell Production
Allogeneic natural killer (NK) cells appear promising as an adoptive cell therapy (ACT) that targets cancer. They’re limited, however, by production methods that can’t readily produce these cells in therapeutically relevant quantities.
Researchers led by Sang-Ki Kim, DVM, PhD, professor, Kongju National University in Korea, and CSO at Vaxcell Bio, along with Seung-Hwan Lee, PhD, professor, University of Ottawa, appear to have solved that bottleneck with an engineered version of the feeder cell line known as ARH-77, a B-lymphoblast cell line that stimulates NK cells. Even in its unmodified form, ARH-77 cells expanded NK cells extracted from peripheral blood samples 681-fold after 28 days. In contrast, K562, the cell line typically used, enabled 155-fold expansion during that time.
That expansion pales in comparison to that of the engineered cell line. The now-modified ARH-77 cells, modified to express four specific stimulatory ligands, expanded NK cells by 101,241-fold in 28 days. Making the same modifications to the K562 cells, however, improved production only 4.4-fold. In each of the cell lines, purity and cytotoxicity were considered equivalent.
Kim, Lee, and colleagues chose the ligands B7-H6, CD137L, IL-15, and IL-15Rα to provide multi-axis stimulation to enhance NK cell activation and proliferation as well as to enhance persistence. For example, B7-H6 stimulates production and exhibits early cytotoxic benefits, but those benefits dissipated by week four. CD137L appears to compensate for that attenuation, the scientists report. Notably, the feeder performance was consistent across donors.
While these ligands were more effective than other ligands the team considered, they stress that more work is needed to “formally establish the added value of each ligand.” They also want to evaluate the engineered ARH-77 in terms of in vivo persistence and anti-tumor activity against additional models. Large-scale manufacturing constraints also should be considered in future studies.
Because feeder cell performance is considered stable across the donor population, Kim and Lee suggest their engineered ARH-77 cell line may be a reliable option for NK cell expansion as therapeutic production scales up. As the scientists note, “These findings establish ARH-77 as a promising alternative feeder cell platform that could enhance the scalability, consistency, and potency of allogeneic NK cell manufacturing for clinical adoptive immunotherapy.”
The post Novel Feeder Cell Line Dramatically Expands NK Cell Production appeared first on GEN – Genetic Engineering and Biotechnology News.
Recoded E. coli Promises More Scalable Weight Loss Drug Production
The manufacturing of weight loss drugs at large scale could get cheaper and more sustainable thanks to an engineered strain of Escherichia coli (E. coli) bacteria.
The fully recoded E. coli, designed to use only 61 codons to synthesize proteins, is now being rolled out as a new method for manufacturing peptides with non-natural chemistries.
That’s according to Constructive Bio, the company that recoded the E.coli and now hopes this synthetic strain will transform the production of some high-volume hard-to-manufacture protein/peptide therapeutics.
“Our key message is that we’re able to produce long peptides containing non-canonical amino acids to deliver therapeutic proteins at scale by biomanufacturing,” explains Rob Salmon, PhD, head of bioprocess at Constructive Bio.
“And our key differentiator is there’s currently a market in, for example, weight loss drugs.”
According to Salmon, glucagon-like peptide-1 (GLP-1) agonists for weight loss are currently produced using chemical synthesis approaches such as solid phase peptide synthesis, which is hard to scale and generates high volumes of toxic waste.
By contrast, the synthetic E. coli strain can potentially produce these peptides using fermentation via standardized industrial processes, he says.
“We want to fit into standardized industrial unit operations and, through that, scale to thousands of liters of product that we can sell to the market,” he explains.
The strain was developed as part of research into reducing the number of codons needed to synthesize proteins in an organism from 64 to 61, allowing slots for three new non-canonical amino acids, according to the company.
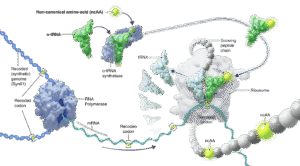
Constructive Bio was founded in 2022 to take the strain forward into industrial applications, including optimizing for applications such as antibody fragments or the long peptides used for GLP-1 agonist therapies.
Since then, the optimized strain has been taken through some industrial fermentations and demonstrated promising titers, he explains, adding that he will present results at the upcoming Bioprocessing Summit in Boston.
“We’re challenging some of the assumptions from chemists that biology can’t be used to do this,” he says.
The post Recoded <i>E. coli</i> Promises More Scalable Weight Loss Drug Production appeared first on GEN – Genetic Engineering and Biotechnology News.
Scaling Stem-Cell Manufacturing for Therapies
Human pluripotent stem cells (hPSCs) have long been viewed as one of regenerative medicine’s most promising raw materials. Now, as more than 100 clinical trials evaluate hPSC-derived therapies for diseases ranging from Parkinson’s disease to heart failure and type 1 diabetes, attention is turning toward a crucial challenge: how to manufacture these cells reliably and economically at industrial scale.
According to Kevin Cyrys and Robert Zweigerdt, PhD, both of Hannover Medical School in Germany, the field has entered a new phase. Rather than simply demonstrating that stem cells can be grown in bioreactors, researchers are increasingly focused on creating robust production platforms that can deliver consistent quality across facilities and patient populations.
“Human pluripotent stem cells can serve as an unlimited, renewable ‘raw material’ for essentially any therapeutic cell product,” the authors wrote, highlighting the technology’s potential to overcome limitations associated with donor-derived tissues and organs.
The manufacturing challenge is substantial. While some therapies, such as treatments for age-related macular degeneration, require only tens of thousands of cells per dose, others may demand billions of cells for a single patient treatment. Conventional laboratory-scale methods are unlikely to meet such requirements efficiently.
To address this gap, developers are increasingly adopting three-dimensional suspension cultures in bioreactors. Compared with traditional two-dimensional cell culture systems, bioreactors provide tighter control over temperature, oxygen levels, pH, and carbon dioxide while supporting automated, closed-system manufacturing compatible with good manufacturing practice (GMP) standards.
The field has already demonstrated notable progress across multiple therapeutic areas. Researchers have developed scalable processes for producing cardiomyocytes, pancreatic islet cells, hepatocyte-like cells, neural tissues, and immune effectors derived from hPSCs. Some cardiac manufacturing platforms have reported production of billions of cardiomyocytes in liter-scale bioreactors, while immune-cell manufacturing programs have successfully expanded induced pluripotent stem cell-derived natural killer cells in 1–10 L systems while maintaining product quality.
Yet scaling production involves more than increasing cell yields. “Industrial-scale success depends on more than headline totals,” Cyrys and Zweigerdt note, citing the importance of volumetric productivity, production time, reproducibility, and integration of expansion, differentiation, and downstream processing into a coherent GMP-ready workflow.
Looking ahead, Cyrys and Zweigerdt argue that the next generation of stem-cell manufacturing will be defined by data-driven process control. They predict that AI-enabled systems will help move the industry from retrospective quality analysis toward real-time decision support, ultimately improving comparability between batches and strengthening product definitions across manufacturing networks.
Despite ongoing challenges involving cost, quality control, and regulatory compliance, the authors conclude that stem-cell bioprocessing has already crossed an important threshold. Scalable culture systems are no longer the primary obstacle. Instead, the focus has shifted toward engineering reliable industrial processes capable of transforming complex stem-cell biology into reproducible therapeutic products.
The post Scaling Stem-Cell Manufacturing for Therapies appeared first on GEN – Genetic Engineering and Biotechnology News.
WHO Selects NIBRT as Training Hub to Help LMICs Build Biopharma Capacity
Ireland’s National Institute for Bioprocessing Research and Training (NIBRT) will help biopharma engineers hone their automation and AI skills as part of a new World Health Organization (WHO) network.
The WHO named the University College Dublin-based organization as its newest training center, explaining it will provide engineers with context-specific skills courses aligned with “regional priorities, regulatory environments.”
NIBRT spokesman Killian O’Driscoll tells GEN, “Following a competitive application process, NIBRT has now been designated as the WHO Training Center for the European Region. NIBRT will work with partners and stakeholders to identify the skills gaps within the region and provide the appropriate training solutions, which will involve a blend of online, classroom, and practical training on biopharma manufacturing.”
Engineers who take part will be taught how to use advanced bioprocessing technologies in a variety of manufacturing settings, according to O’Driscoll, who says the plan is to use the organization’s syllabus as a foundation.
“Training will cover all aspects of biopharma manufacturing based on NIBRT’s award-winning curriculum, including drug substance, drug product, QC, engineering, digitalization, etc. Automation, digitalization, AI, and related areas are a core component of the NIBRT curriculum and will form part of the training solutions,” he adds.
LMIC capacity
The WHO established the Biomanufacturing Workforce Training Initiative in 2023 to address critical skills gaps across the biomanufacturing value chain and enable countries to translate technological advances into sustainable local production.
NIBRT is now one of seven institutions selected. The rest of the network consists of the Institut Pasteur de Dakar in Senegal, the Council for Scientific and Industrial Research in South Africa, the Oswaldo Cruz Foundation in Brazil, the Translational Health Science and Technology Institute in India, Egypt’s Center for Continuing Professional Development, and Peking University in China.
The initiative directly supports World Health Assembly resolution WHA74.6, which called on member states to strengthen local production of medicines and other health technologies to prepare for emergencies.
This will be a focus of NIBRT’s training activities, according to O’Driscoll.
“One of the key actions the WHO identified following the COVID-19 pandemic was to increase biopharma manufacturing capabilities within lower-middle-income countries (LMICs). The WHO’s Biomanufacturing Workforce Training Initiative addresses critical skills gaps in the biomanufacturing value chain to support sustainable local production of vaccines and biotherapeutics in LMICs,” he says.
In a press statement, director-general, Tedros Adhanom Ghebreyesus, PhD, said, “We have designated regional training centers in each of WHO’s six regions to build the skilled workforce needed to sustain local production of vaccines and biologics. They will operate as part of a coordinated global network, delivering context-specific training aligned with regional priorities, regulatory environments, and languages.”
The post WHO Selects NIBRT as Training Hub to Help LMICs Build Biopharma Capacity appeared first on GEN – Genetic Engineering and Biotechnology News.
Europe’s extreme heat is shutting down power plants
Europe is in the middle of a record-breaking heat wave, and the grid is being pushed to its limits as people turn to fans and air-conditioning to try to stay cool. Some power plants won’t be online to help handle the load.
On June 23, France saw its hottest day since record-keeping began in 1947. Temperatures climbed to over 44 °C (111 °F), and overnight temperatures remained unusually high. This prolonged hot weather warmed up the water in some rivers across the country, a problem for the many nuclear plants that rely on those bodies of water for cooling. One reactor has already shut down, and others are being ramped down or will see limitations later in the week.
Unit two at the Golfech nuclear power plant in southern France shut down at about 11:45 p.m. on June 22 when the river used to cool the plant got too hot. The move was a precautionary measure, according to Brid Nelligan, a spokesperson for EDF, the plant’s owner and operator.
The power plant takes in water from the Garonne River and then returns most of it to the river at slightly higher temperatures after using it to cool equipment. French regulations limit the temperature of that return stream, so the warm water (it was expected to reach 28 °C, or around 82 °F) forced the operator to shut down the plant.
EDF, which operates France’s entire nuclear fleet, is also limiting the output of other reactors across the country—one reactor at the Nogent-sur-Seine power plant was ramped down as of Tuesday, and more will follow later in the week, Nelligan says.
Extreme heat has affected France’s nuclear industry before. At least seven gigawatts’ worth of nuclear energy was forced to shut down across the country during a heat wave in July 2025, according to data from Ember Energy. That’s more than the entire grid of Ireland.
This time, power plant outages and limitations aren’t expected to be drastic enough to affect the ability to meet demand in France, according to RTE, operator of the national electric grid.
Nuclear power has made most of the headlines during this heat wave, but other forms of electricity generation face similar challenges. Hydropower plants frequently run into problems when dry conditions lower the amount of water available to generate energy and force them to decrease or shut off operations. In the first five months of 2025, high temperatures and low water conditions cut hydropower supplies in Europe by 13% compared with the year before.
Even established coal and natural-gas plants can be challenged by high temperatures. Hot weather can stress equipment and limit the efficiency of cooling towers. Five gas plants across the UK have reported output reductions due to the conditions, cutting a total of about 2.5 gigawatts from the power supply.
Increased demand, largely driven by cooling, is the main factor stressing Europe’s power grid, says Jean-Paul Harreman, director of Montel, an energy intelligence provider, via email. Even countries that haven’t historically relied much on cooling technologies are turning to them now—the number of UK homes that use air-conditioning has roughly doubled since 2022.
Around the world, the challenges heat presents for the grid are only expected to get worse as climate change brings more frequent and intense heat waves. Globally, energy use for cooling is set to double by 2050 relative to 2023 levels, according to the International Energy Agency.
“Utilities can adapt by planning for summer peaks, making cooling demand more flexible, reinforcing grids for high temperatures, deploying batteries and demand response, and climate-proofing power plants’ cooling systems,” says Simone Tagliapietra, senior fellow at Bruegel, an economic and policy think tank, via email.
But those changes could be expensive. Earlier this year, EDF shared a climate-change vulnerability assessment for its business, including nuclear and hydropower operations across France. Upgrades are expected to cost about €600 million per year (about $680 million) over the next 15 years.
Meanwhile, high temperatures are expected to continue across much of Europe through the end of the week.
STAT+: A dispatch on AI from BIOtech’s big summer bash
You’re reading the web edition of STAT’s AI Prognosis newsletter, our subscriber-exclusive guide to artificial intelligence in health care and medicine. Sign up to get it delivered in your inbox every Wednesday.
I’m writing to you from a hotel room in San Diego, four hours before this newsletter is scheduled to send.
I’m also still reeling from this absolutely crazy story my colleague Lizzy Lawrence wrote. Imagine STAT executive editor Rick Berke reading of the top of the story out loud to a group of STAT reporters over dinner at a waterfront restaurant, and my jaw dropping as I realize what’s going on.
Medra Launches Reasoning Layer for Drug Discovery Robotics
As AI infrastructure for drug discovery continues to proliferate with reasoning workflows capable of generating hypotheses, candidate molecules, and experimental plans, Medra CEO Michelle Lee, PhD, argues that physical AI is the solution to addressing the next bottleneck: experimental validation at scale.
“Building foundation models in biology that can predict and cure disease will take thousands of years of data generation,” Lee explained in an interview with GEN Edge. “The more I looked at the field, the more I realized that this data problem is actually a robotics problem.”
In a new collaboration with the Defense Advanced Research Projects Agency (DARPA), Medra has launched AI Experimentalist, the scientific reasoning layer of its robotics platform. The system translates high-level research goals expressed in natural language into executable workflows that span the entire experimental cycle, from literature review, wet-lab execution, data analysis, and protocol refinement.
In a blog post, Medra presents an example where scientists prompt to “build an Epidermal Growth Factor Receptor (EGFR) blocking antibody assay cascade.” AI Experimentalist can propose small optimizations in execution, including testing linear DNA templates in parallel, optimizing expression conditions, and feeding results immediately into the next run, for compounding time savings from days to hours.
Partners can access AI Experimentalist through physical AI labs deployed on site at customer facilities or operated remotely through Medra’s flagship science laboratory, Medra Lab 001 (ML001), which unveiled in April and touts running experiments 24/7. Medra describes the 38,000 square foot facility as the largest autonomous lab in the United States.
Artisanal nature
In contrast to industrial automation, which has been powerful for repeatable tasks, such as combinatorial chemistry and screening, physical AI equips the same hardware with sensors to enable intelligent decision-making.
While many robotics players in biology are focused on the manufacturing step, Medra has the ambitious goal of accelerating end-to-end drug discovery campaigns.
“The artisanal nature of science is actually what makes certain experiments work and others fail,” said Lee. She noted that seemingly subtle variables, such as the angle of a pipette or the precise timing of mixing reagents, can have an outsized impact on experimental outcomes.
Medra is currently working with partners across academia, biopharma, and government to run and develop assays across a wide array of applications, including antibody discovery, protein engineering, gene editing, and cell biology.
Looking ahead, Lee says the bottleneck is not robotic capability, but integration and deployment. AI Experimentalist addresses this challenge through a multi-agent architecture and model-agnostic harness that allows Medra to incorporate new biological AI models and scientific agents. Among them are NVIDIA Nemotron models for protocol editing and optimization and the newly launched NVIDIA BioNeMo Agent Toolkit.
“The flexibility of physical AI will be incredibly key in making scientific discovery truly autonomous,” asserts Lee.
The post Medra Launches Reasoning Layer for Drug Discovery Robotics appeared first on GEN – Genetic Engineering and Biotechnology News.