
Background: Simulation-based training has established itself as integral to clinical education, particularly for high-stakes, low-frequency pediatric emergencies. Innovations incorporating virtual reality (VR) are rapidly gaining traction for offering scalable, repeatable, and immersive opportunities for scenario-based learning. Understanding its role and applicability in postgraduate pediatric training, however, remains limited, with further exploration required into how pediatric trainees perceive, conceptualize, and anticipate VR-based simulation within real-world training contexts. Objective: This study explored London-based pediatric trainees’ perceptions of VR simulation as an adjunct for developing skills in recognizing and managing critically ill children. Methods: An exploratory mixed methods study was conducted among pediatric trainees across all training levels within the London School of Paediatrics between April 2024 and July 2024. Data were collected using a 35-item online questionnaire containing Likert-scale, categorical, and open-ended questions, alongside virtual semistructured interviews. The questionnaire explored current training practices; confidence and preparedness in managing critically ill children; familiarity and experience with VR; and perceived benefits, limitations, barriers, and facilitators to adoption. Quantitative data were analyzed descriptively, with exploratory Mann-Whitney tests and Spearman correlations where appropriate. Internal consistency of key domains was assessed using Cronbach α. Qualitative data from open-ended responses and interviews were analyzed thematically using the Braun and Clarke reflexive approach. Quantitative and qualitative strands were integrated at the interpretation stage to contextualize survey patterns with illustrative qualitative insights. Results: Thirty trainees participated in the survey (30/450, 6.7%; female: 16/30, 53%), with participants spanning all 8 training years. Two senior trainees participated in interviews. Clinical exposure or experience and simulation training were identified as central to developing skills in managing pediatric emergencies. Trainees also described limited exposure to high-acuity scenarios; variable access to high-fidelity simulation; and constraints related to workload, supervision, and feedback. Most participants (21/30) had no prior VR exposure in a medical setting, while 17% (5/30) had used VR training, and all reported positive experiences. Despite limited exposure, 93% (28/30) of participants were willing to try VR simulation for exposure to rare scenarios, structured decision-making, and confidence-building. Key perceived barriers included high cost (24/30, 80%), technological literacy (17/30, 57%), infrastructure (15/30, 50%), and limited stakeholder familiarity or support (25/30, 83%). Participants suggested taster sessions, faculty advocacy, leadership engagement, and phased implementation as potential facilitators. Internal consistency of attitudinal survey items was good (Cronbach α=0.80). Conclusions: Despite limited exposure, pediatric trainees viewed VR simulation as a valuable adjunct to existing critical care training, particularly for those in earlier stages of training. However, these findings represent anticipatory perceptions rather than evidence of educational effectiveness. The implementation of VR will depend on addressing key infrastructural, organizational, educational, and equity-related barriers. Further multicenter studies are needed to evaluate the educational impact and feasibility, learning outcomes, and cost-effectiveness in postgraduate pediatric critical care training programs.
<img src="https://jmir-production.s3.us-east-2.amazonaws.com/thumbs/5e89b66792fb5f3200ddaea0256600ff" />
Repositioning retail for the AI era
Artificial intelligence is rapidly reshaping retail, but not in the ways consumers might immediately notice. The biggest transformation may not be flashy virtual try-ons or chatbot shopping assistants, but in how decisions are made behind the scenes: how products surface in search results, how inventory moves through supply chains, how engineers ship code faster, and how retailers respond to customer behavior in real time. As legacy retailers navigate a fragmented and hyper-competitive landscape, AI is becoming an operating philosophy.
At Macy’s, that philosophy is more often defined by what senior director of engineering Murali Murugan describes as an “AI-first” approach. “AI first isn’t about adding intelligence on top,” Murugan says. “It’s about redesigning how decisions happen so the business moves faster and every experience feels more relevant by default.” Rather than layering AI onto existing workflows, Macy’s is embedding intelligence directly into systems that include personalization, search, operational planning, and software development itself.
The company’s strategy is reflective of a larger shift taking place across retail: moving from isolated AI pilots toward integrated systems designed to compress, as Murugan puts it, “the gap between the signal and the action.” Early efforts focused on narrow, high-impact use cases like search recommendations and customer engagement, where measurable gains in conversion and reduced friction quickly built internal momentum. “Once we established the quick wins, scaling was a business decision, not a technology debate anymore,” he says.
That momentum is now extending into conversational commerce through tools like Ask Macy’s, an AI-powered shopping assistant designed to act more like a personal stylist than a traditional search bar. Whether for a prom, a vacation, or a last-minute event, customers can describe what they need conversationally and receive curated recommendations informed by past purchases, preferences, and context.
Still, the company sees AI as more of an invisible layer augmenting human judgment than a replacement for it. The long-term vision is retail that feels increasingly seamless, adaptive, and personalized, powered by systems customers may never even notice are there.
“The real transformation in this all comes from continuous improvement,” Murugan says. “It’s about learning from the mistakes, quickly adapting to the newer technology standards that are coming into play, timing, and execution which compound into a meaningfully better customer experience.”
This webcast is produced in partnership with Infosys.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
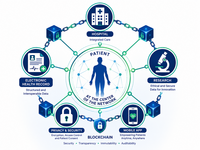
Patient Perceptions and Acceptance of Blockchain-Based Health Data Sharing in Oncology: Cross-Sectional Survey
Background: Fragmentation of electronic health records in oncology hinders coordinated care, delays diagnoses, and limits therapeutic personalization. Blockchains promise to promote secure, interoperable, and patient-centered data governance; however, patient perceptions of blockchains remain underexplored, particularly in middle-income countries such as Brazil. Objective: We assessed opinions, attitudes, and willingness among patients with cancer to digitally share clinical information and the feasibility of applying blockchains to restructuring secure health data sharing in the Brazilian public health context. We had three research questions: (1) What is the level of digital health tool acceptance among patients with cancer in Brazil? (2) Which sociodemographic factors are associated with willingness to share health data? (3) Are blockchains feasible and acceptable for restructuring secure oncology data sharing? Methods: An exploratory, descriptive, cross-sectional self-report survey was conducted at Hospital Santa Izabel, a national oncology reference center in Salvador, Bahia, Brazil, between September and November 2023. A convenience sample of 110 outpatients with cancer was recruited systematically; data were collected via a self-administered questionnaire. The 20-item instrument, developed de novo and validated via expert panel and pilot testing, covered 5 content domains yielding 3 composite scoring domains: self-management, adherence, and governance. We used Cronbach α to assess internal consistency, independent 2-tailed tests, 1-way ANOVA, and Pearson correlations to compare domain scores across sociodemographic groups, and a chi-square goodness-of-fit test to examine trust proportions across recipient types. Results: We received sufficiently complete responses from 94.5% (104/110) of patients. The sample was predominantly female (63/98, 64.3%), self-identified as (mixed-race; 64/98, 65.3%), and lower income (55/96, 57.3% earned less than twice the minimum wage). Acceptance of technology was high: 86.4% (95/110) would use health apps and 89.1% (98/110) expressed interest in prevention-focused applications. Trust in data sharing varied significantly across recipient types (=210.4; <.001): 79.1% (87/110) trusted health care professionals, 51.8% (57/110) hospitals, 15.5% (17/110) the pharmaceutical industry, and 10% (11/110) the government. Anonymization and encryption significantly increased willingness to share (92/110, 83.6%). Younger patients (18‐59 years) showed significantly higher adherence scores than those aged ≥60 years (mean 76.49, SD 19.16 vs mean 65.83, SD 26.66; =2.29; =.02). Domain reliability was good to excellent (Cronbach α=0.8807 [adherence], 0.8504 [self-management], and 0.7576 [governance]). Conclusions: Patients with cancer in Brazil demonstrated high acceptance of digital health tools and openness to data sharing when privacy, security, and governance are guaranteed. This supports the feasibility of blockchain-based health data management systems, provided they incorporate patient-centered principles, digital inclusion strategies, and robust governance aligned with Brazilian regulations (the General Data Protection Law) and the Unified Health System (Sistema Único de Saúde) infrastructure. Importantly, patient support reflected acceptance of blockchain’s functional principles, data security, anonymization, and auditability rather than familiarity with the technology itself, a distinction with direct implications for future implementation studies. International Registered Report Identifier (IRRID): RR2-10.2196/89278
Omega 365 platform selected for Frimley hospital programme
Frimley Health NHS Foundation Trust has selected Omega 365’s system to support its major hospital development programme.
The Download: Europe’s heat wave hits the grid, and IBM’s chip targets Moore’s Law
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Europe’s extreme heat is shutting down power plants
Europe is in the middle of a record-breaking heat wave, and the grid is being pushed to its limits as people turn to fans and air-conditioning to try to stay cool. But some power plants won’t be online to help handle the load.
The main source of stress is increased demand, largely driven by cooling. And the challenges are only expected to worsen as climate change brings more frequent and intense heat waves.
Find out how rising temperatures are stretching power supplies—and how utilities can adapt.
—Casey Crownhart
What Europe’s heat wave means for the power grid
Grid planning in the age of climate change generally means that we need a lot more supply, and quickly. But one interesting facet to this challenge is that in some places, seasonal patterns are shifting, compounding the difficulty of meeting demand.
Europe has historically seen its grid peak in the winter when electric heating is widespread. So some planned outages happen in the spring and into the summer, which is affecting the supply right now. But a growing need for air-conditioning will alter the balance.
Read the full story on how climate change is reshaping electricity demand.
—Casey Crownhart
This story is from The Spark, our weekly newsletter giving you the inside track on all things climate. Sign up to receive it in your inbox every Wednesday.
IBM unveils chip technology that could help extend Moore’s Law another decade
IBM has built a new prototype chip with around 100 billion transistors on an area the size of a fingernail. That’s twice the density of the company’s previous state-of-the-art technology announced in 2021. And the design could pave the way for faster and more energy-efficient computers for years to come.
In the last fifteen years, transistors have been shrunk close to their limits. They can’t get smaller without their function deteriorating. IBM’s new chip resolves this with an approach familiar to urban planners: building up.
Here’s how the strategy is bringing new hope to the technology industry.
—Sophia Chen
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Anthropic says Alibaba “illicitly” extracted Claude’s capabilities
It claims the Chinese firm ran a “brazen” campaign to access the model. (BBC)
+ It says it’s the “largest known distillation attack” on the company. (CNBC)
+ The technique trains a weaker model on a stronger one’s outputs. (FT $)
+ Anthropic previously accused other Chinese rivals of using it. (CNN)
+ But it’s still feuding with the White House. (MIT Technology Review)
2 NASA has detected possible chemical signatures of ancient life on Mars
The Perseverance rover spotted complex carbon on rocks. (New Scientist $)
+ The molecules are typically associated with dead organisms. (Guardian)
+ The US has lost its lead in the hunt for alien life. (MIT Technology Review)
3 The EU has joined a US pact to stop relying on Chinese AI
Much of the rest of the world seems to still be a battleground for control. (FT $)
+ China is expanding its AI push in the Global South to counter the US. (The Wire China)
+ Chinese AI experts are freaking out about the AI arms race. (Wired $)
4 OpenAI and Broadcom have unveiled their first jointly designed AI chip
Jalapeño is built to power large-scale AI systems like ChatGPT. (NYT $)
+ It’s part of OpenAI’s push to “build the full stack.” (CNBC)
5 A new report shows ICE has built a vast hi-tech surveillance system
It includes facial recognition, drones, and data scraping.(Guardian)
+ Is the Pentagon allowed to surveil citizens with AI? (MIT Technology Review)
6 Electronics can now be printed onto living tissue
Which could enable smart implants and ingestible diagnostics. (The Economist $)
7 The data center boom is sparking a third wave of inflation
Demand for memory chips is pushing prices higher.(WSJ $)
8 Companies are scrambling to curb spending on AI token “chewing”
Accenture data shows non-technical staff are draining budgets. (404 Media)
9 Claude Design is creating a bland wave of website uniformity
The AI tool is homogenizing the internet’s aesthetic. (The New Yorker $)
10 Elon Musk has lost his trillionaire status
Thanks to SpaceX stock coming back to Earth. (Business Insider)
Quote of the day
“Tom Brown is not being a weirdo like Dario and can actually engage.”
—A person directly familiar with calls between the Trump administration and Anthropic tells Wired that they’ve improved since cofounder Tom Brown replaced CEO Dario Amodei in the talks.
One More Thing

TONY LUONG
The quest to learn if our brain’s mutations affect mental health
For years, scientists searching for the roots of conditions like schizophrenia, autism, and Alzheimer’s have focused on single genes. But the real source may lie in a more complex genetic puzzle inside the brain.
Mike McConnell has spent decades exploring the idea that neurons do not all share identical DNA, and that these differences could help explain psychiatric disease. His work has contributed to evidence that brain cells can form a “genetic mosaic,” with mutations that vary across the brain.
Discover how this could reshape our understanding of mental illness.
—Roxanne Khamsi
We can still have nice things
A place for comfort, fun, and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ This classical reimagining of the Super Mario soundtrack is exquisite.
+ At long last, we can calculate the fuel efficiency of launching our enemies into the Sun.
+ Before CGI, explosions were an art form. This compilation of classic practical effects is pure action-movie nostalgia.
+ Cambridge botanists lovingly recreated a 336-year-old garden to honor the “father of natural history.” (Big thanks to reader Peter Ryan for the find!)
Biological performance evaluation of graphene nanoplatelets for intracranial direct current stimulation
Graphene nanoplatelets (GNPs) offer promising properties for neural interface applications, particularly in intracranial direct current (DC) stimulation, due to their high charge injection capacity, flexibility, and biocompatibility. In this study, we comprehensively evaluate the biological and functional performance of GNP-based electrodes for acute and chronic cortical stimulation and recording. GNP electrodes were fabricated via screen-printing on flexible polyimide substrates. They were assessed for cytotoxicity using RAW 264.7 macrophage cell lines and primary hippocampal cultures, showing no evidence of cell death or toxicity. Long-term implantation in non-human primates (50 days) revealed no signs of infection, inflammation, or cortical damage, supporting the biostability of the material. Magnetic resonance imaging confirmed that GNPs produce no imaging artifacts, affirming their compatibility with standard neuroimaging protocols. Functionally, epidural DC stimulation using GNP electrodes modulated neuronal firing rates in the auditory cortex in a polarity-dependent manner, consistent with classical effects of DC stimulation. Furthermore, the same electrodes reliably recorded auditory-evoked potentials, demonstrating dual functionality for stimulation and recording. These findings position screen-printed GNP electrodes as safe, versatile, and effective tools for neurophysiological applications, and highlight their potential for future use in translational neuroscience and neurotherapeutic settings.
Impaired task-dependent cerebral cortex oxygenation in Glut1 deficiency
IntroductionNeuronal activation increases regional glucose utilization and requires coordinated increases in tissue oxygenation. While glucose uptake is regulated by cell type-specific transporter expression, oxygen diffuses more broadly across brain tissue, linking cerebral blood flow to measurable changes in oxygenation using functional near-infrared spectroscopy (fNIRS). In glucose transporter type 1 deficiency (G1D), reduced brain glucose and glycogen levels suggest limited substrate availability to support neural activity.MethodsIndividuals with G1D and age-matched controls underwent fNIRS while performing standardized cognitive tasks. Task-evoked changes in oxygenated and deoxygenated hemoglobin were recorded to quantify cortical activation and regional oxygenation responses.ResultsWe hypothesized that task-dependent metabolic responses are constrained in G1D. Consistent with this hypothesis, fNIRS measurements demonstrated reduced cortical oxygenation responses in individuals with G1D compared with controls.DiscussionThese findings support an altered neuroenergetic response to neural activation in G1D, in which cognitive performance is preserved despite limited substrate availability and attenuated oxygenation responses, consistent with adaptive or compensatory mechanisms.
Toward mechanistic virtual immune cells
Nature Biotechnology, Published online: 25 June 2026; doi:10.1038/s41587-026-03139-8
This Comment outlines molecular and technical considerations for developing mechanistically grounded virtual immune cell models.
Metabolic determinants of cancer immunotherapy outcomes identified by plasma profiling
Nature Medicine, Published online: 25 June 2026; doi:10.1038/s41591-026-04481-9
Mass-spectrometry-based metabolomic analysis of plasma samples from multiple cohorts of patients treated with immunotherapy across five distinct tumor types, followed by machine learning enabled identification of metabolic signatures, as well as functional exploration, reveals association of increased plasma histidine levels with prolonged survival and its potential for therapeutic intervention.
Neoadjuvant stereotactic body radiation therapy with durvalumab and oleclumab in ER+HER2− breast cancer: a randomized phase 2 trial
Nature Medicine, Published online: 25 June 2026; doi:10.1038/s41591-026-04453-z
In the randomized phase 2 Neo-CheckRay trial, patients with early-stage ER+HER2− breast cancer received neoadjuvant immune-modulating stereotactic body radiation therapy with or without durvalumab, and with or without the anti-CD73 antibody oleclumab, leading to encouraging clinical responses when durvalumab was added including in patients with PD-L1-negative tumors.