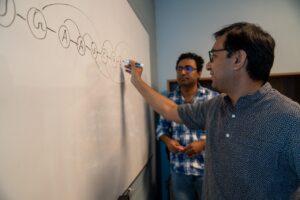Anthropic has released Claude Science, an AI workbench for scientists that consolidates fragmented research tools, including over 60 scientific databases and connectors pre-configured for genomics, proteomics, structural biology, and more, into a single reasoning layer. The platform joins an increasingly crowded ecosystem of tech platforms specialized for biology and aims to accelerate scientific discovery by making domain expertise more accessible.
Anthropic’s life science partners are delivering applications. Basecamp Research is targeting global public health, where drug-resistant infections play a role in nearly five million deaths per year. The London-based team has announced that its antibiotic design and vaccine target prediction EDEN models will now be available through Claude Science.
A metagenomic foundation model, EDEN demonstrated a 97% success rate when designing functional peptides with high potency against World Health Organization (WHO) critical-priority and multidrug-resistant pathogens. The work was done in collaboration with César de la Fuente, PhD, presidential associate professor at the University of Pennsylvania.
In a Claude Science demo, Oliver Vince, PhD, co-founder at Basecamp, uploaded a sample patient microbiology report. When given a simple natural language prompt, the platform designed peptides, predicted their efficacy, and provided a shortlist of candidates most likely to succeed in experiments in minutes.
While generating human-ready antibiotics at the click of a button is still a step away, Vince said democratizing these tools is a powerful first step, particularly for researchers in regions where accelerated computing infrastructure is not readily accessible.
“Most models require you to be a computational scientist,” Vince told GEN Edge. “Now, potentially any clinician in the world can chat with Claude and design an antibiotic that may work.”
“From a strategic perspective, you want the people with the most agency to solve the problem,” added Phil Lorenz, PhD, CTO at Basecamp. “Not the model builders who are two or three steps removed.”
Full stack
Founded in 2019, Basecamp has spent its initial years building a full computational stack spanning data, models, and therapeutic assets.
In addition to antibiotics and vaccines, the company’s U.S. office, based in Cambridge and led by Jonathan Finn, PhD, Basecamp CSO and former CSO of Tome Biosciences, has fine-tuned EDEN for programmable gene insertion. The approach places large therapeutic DNA sequences at precise locations in the human genome, expanding upon CRISPR-based approaches that use small edits to address a limited number of indications.
EDEN’s generalizability is enabled by training on BaseData, the company’s proprietary dataset composed of 9.8 billion protein sequences collected over 200 diverse and extreme locations, including thermal springs, polar ice, and high-altitude plateaus, across more than 30 countries. The database provides a 10-fold expansion of known protein diversity when compared to all public databases combined.
In March, the team published the compounding advantages of BaseData on model performance in a technical report on scaling laws for metagenomics. Basecamp is steadily pushing forward that data diversity through the Trillion Gene Atlas, a partnership with Anthropic, NVIDIA, PacBio, and Ultima Genomics that aims to scale BaseData 100-fold over the next two years.
Vince emphasizes that model deployment and integration into real-world workflows will be critical for these models to reach their full potential. Basecamp anticipates releasing more applications over the next year.
“I think it will surprise people what these models can do,” he said.
Biomedical engineers at Duke University have for the first time used induced pluripotent stem cells (iPSCs) to grow specialized blood vessel cells critical to retinal health.
When injected into mouse models of retinal disease, these “retinal endothelial cells” (iRECs) integrated into the damaged tissue to regenerate blood vessels and restore retinal function. The team also demonstrated these cells’ ability to form functional retinal vascular tissue in a lab-grown environment, providing a pathway to model and research various eye diseases.
The results point toward the potential of using these retinal cells and models to develop new methods of impactful vision loss treatments and eye disorder research. “Retinal vascular diseases affect millions of people in the U.S., but our understanding remains limited, hindering our ability to discover and develop new therapeutics,” said Sharon Gerecht, PhD, the Paul M. Gross Distinguished professor and chair of Biomedical Engineering at Duke. “Using human stem cells, we generated the cells found in retinal blood vessels, paving the way for new therapeutic approaches.”
The old saying that the eyes are windows into the soul is more accurate than one might think. Neurons from the retina—the back part of the eye that detects light—extend directly to the brain, technically making the eyes part of the central nervous system.
Also like the brain, the retina has a blood barrier that strictly controls what gets in and out including oxygen, nutrients, water and pharmaceuticals. While this barrier keeps the retina healthy and relatively protected from disease-causing agents, it also makes treating the retina difficult. “Retinal tissue has the highest energy and oxygen usage in the body due to the retina’s intense and continuous neuronal activity,” the authors further explained. “This demand leads to a crucial reliance on the inner blood–retina barrier (iBRB) to maintain ocular homeostasis.”
The barrier is formed by blood vessel tissue comprising a tight network of retinal endothelial cells, which form the inner layer of blood vessels, in concert with other specialized cells called pericytes and astrocytes. “Retinal endothelial cells (RECs) in the iBRB are continuous endothelial cells (ECs) that form tight junctions to regulate the diffusion of small molecules, such as ions and water, across their cell–cell interface,” the investigators continued. The specificity of these cells and the fact that they do not form in other areas of the body make the complex tissue difficult to heal or to grow from scratch.
This image depicts both healthy (right) and deteriorated (left) human retinal endothelial cells, which are essential for maintaining eye sight. The deterioration is caused by low oxygen and high glucose levels, mimicking conditions found in diabetic retinopathy, the leading cause of vision loss in working-age people in the United States. [Duke University]
“When this specialized blood vessel tissue begins to break down, it can cause a lot of different diseases that lead to vision loss,” said Parker Esswein, a PhD student working in the Gerecht laboratory and co-first author of the paper. “While there are sources of retinal endothelial cells, being able to grow a continuous supply from scratch could offer many advantages for those working in the field.”
These retinal endothelial cells are currently collected and grown from real patients, making them relatively expensive with a limited supply. “A renewable source of human iBRB endothelium is thus vital for advancing eye research and treatment development,” the team noted in their paper.
To expand access, reduce cost and control variability, the Gerecht lab wanted to see if they could grow them from iPSCs. These are essentially mature adult cells reprogrammed to become primal versions of themselves that can then grow into a wide variety of other cell types.
To do this, Esswein and Ying-Yu Lin, PhD, a former PhD student in Gerecht’s lab, took commercial iPSCs and used a well-established procedure to get them to grow into common endothelial cells that form the inner layer of most of the body’s blood vessels. The researchers then used a specialized cocktail of growth factors to coax the cells into becoming the specific type of endothelial cells found in the retina. “… we differentiated human induced pluripotent stem cells into retinal endothelial cells (iRECs) via the Wnt–β-catenin pathway, namely Norrin–Frizzled4 signaling,” they explained.
Once successful, the researchers put their development to the test. In benchtop experiments, the team was able to get the iRECs to form the same networks and structures that they do within the body. The team then subjected these lab-grown tissues to low oxygen and high glucose levels, which are detrimental conditions often seen within real people. These conditions are fundamental causes of diabetic retinopathy (DR), the leading cause of vision loss in working-age people in the United States, and caused the tissue barrier to break down just like it does in patients. They wrote in summary, “Overall, we were able to robustly recapitulate the DR phenotype in 2D and 3D with our iRECs, exemplifying their ability to be utilized for in vitro disease modeling and to elucidate aberrant pathways and therapeutic targets.”
The researchers then tried their lab-grown cells as a therapy for mouse models with weak, unstructured retinal blood vessels. When injected into the mice before any actual vision loss occurred, these cells successfully integrated into the existing tissue and helped develop strong blood vessels with strong barriers. “When injected into oxygen-induced retinopathy mice, iRECs integrated into the host vascular network and revascularized the ischemic eye, rescuing the tissue,” they stated.
“The tests showed that these lab-grown cells have promise for preventative treatments, especially since they should be easier and cheaper to obtain using our technique,” Esswein said. “And while our benchtop experiments did not attempt to model a wide variety of specific eye diseases in these studies, we’re confident we can create excellent human tissue models in the lab to help better understand these diseases and uncover therapies.”
Moving forward, the researchers are planning to explore these potential uses for their retinal endothelial cells both in their laboratory and through emerging industry partnerships. The group also has a patent pending that covers both the stem cell-based therapeutics and in vitro modeling for drug discovery and testing. In their paper they concluded “Our study establishes functional human iRECs and microphysiological iBRB models that facilitate mechanistic studies aimed at identifying therapeutic targets and promoting the revascularization of injured retinas, thereby supporting treatment advancement.”
Officials at Elsevier say the company is expanding LeapSpace, a research-grade AI workspace, with new agentic capabilities that help “researchers carry out an even greater range of tasks within their complex workflow to drive better outcomes with confidence.”
Designed specifically for the end-to-end research workflow, LeapSpace was created to accelerate discovery, help researchers calibrate the strength of the evidence, and support critical thinking. LeapSpace draws on 20+ million full-text peer-reviewed articles and books from Elsevier and over 1,000 new content licensing partners, including Sage Publishing, Emerald Publishing, IOP Publishing, and NEJM Group. as well as 100+ million scientific records from 7,000+ publishers on Scopus.
Results are grounded in peer-reviewed literature, citations are traceable to sources, Trust Cards help researchers calibrate the strength of evidence, and the researcher remains in control, with every recommended change requiring approval, notes an Elsevier spokesperson.
General-purpose AI tools can generate text, summarize articles and automate some tasks. But researchers require something more demanding: the latest trusted peer-reviewed content, verifiable citations, transparent reasoning, research integrity safeguards, and enterprise-grade security and privacy, according to Stuart Whayman, president, corporate markets, Elsevier, adding that this is what LeapSpace is built for.
Built with research-grade AI, LeapSpace is already delivering results for thousands of researchers around the world: 97% report time savings, with more than half saving over 50% of their research time, points out Whayman, LeapSpace is now extending support to writing—the task researchers most want AI to help with: more than half find writing clearly and concisely to convey complex ideas a challenge, rising to 60% among students and early-career researchers.
Background: Safety planning is recognized as one of the most effective interventions for reducing suicidal behaviors. The quality of safety plans strongly depends on professional training, and traditional methods, such as role-playing, are time-consuming and offer limited opportunities for repetition across diverse patient profiles. Generative artificial intelligence (GenAI) may provide innovative solutions by offering accessible, flexible, and realistic training environments. Objective: This pilot study aimed to evaluate the acceptability and feasibility of a GenAI-based simulator designed to train mental health professionals in safety planning. Methods: Twenty nurses and nursing assistants from psychiatric units in a French university hospital participated in a pre-post, single-session evaluation. After self-rating their ability, competence, and willingness to manage patients experiencing suicidal ideation, participants interacted individually with the text-based simulator for 20 minutes to perform a safety plan with a chatbot, then completed postsimulation acceptability items, and open-ended feedback. Composite scores were computed: acceptability (eg, helpfulness; 0‐40), realism (eg, looking like real interaction with patient; 0‐20), and challenge (eg, emotional challenge; 0‐30). Pre-post changes were tested (Wilcoxon signed-rank test), and age-group comparisons were performed. Results: Acceptability was high (mean 31.9/40, SD 5.3; median 32, IQR 7), realism moderate-to-high (mean 15.1/20, SD 4.1; median 15, IQR 5.25), and challenge manageable (mean 17.0/30, SD 8; median 18, IQR 12.5). Participants rated usefulness (mean 7.65/10, SD 1.57; median 8, IQR 1.57), perceived learning (mean 7.6/10, SD 1.79; median 8, IQR 2), recommendation to use the chatbot for training (mean 8.3/10, SD 1.59; median 9, IQR 2.25), and feedback quality (mean 8.35/10, SD 1.27; median 8.5, IQR 1.25) favorably. Willingness to actively manage patients experiencing suicidal ideation significantly increased postsimulation (.03). Younger participants reported higher acceptability (.04) and realism (.03). Participants reported minimal concerns regarding the simulator’s use. Conclusions: This pilot study demonstrates that a GenAI-based simulator for safety planning is feasible and highly acceptable among experienced mental health professionals. The findings are promising and warrant larger, controlled trials to assess impacts on training effectiveness and patient outcomes.
<img src="https://jmir-production.s3.us-east-2.amazonaws.com/thumbs/662a4ae716b1ea24241b30b661b4ecb7" />
Researchers have developed AI tool to rival the behemoth of Google’s Alphafold 3 in predicting 3D shapes in RNA using less data.
RNAbpFLow could shed new light on the RNA conformational dynamics that underpin diverse cellular processes.
It could also lead to novel RNA-based treatments, such as the messenger RNA vaccines used to prevent COVID-19.
The invention, by two computer scientists at Virginia Tech, generates all-atom RNA conformational ensembles for single-chain RNA monomers.
Unlike several existing deep-learning methods, it can do this without using evolutionary information or homologous structural templates.
The approach is outlined in Nature Methods and the researchers have made the training data, and code freely available.
Study first author Sumit Tarafder, a PhD student, flagged the importance of knowing the shape of an RNA so that it could be targeted.
“In the shape, there are pockets where a drug can attach,” he explained. “If you can’t predict the shape, your pockets are wrong—and the drug won’t work.”
Growing interest in RNA-based therapeutics has driven efforts to determine the 3D structures of RNA.
However, the intrinsic conformational flexibility of RNA presents major challenges when using methods such as X-ray crystallography, nuclear magnetic resonance spectroscopy, and cryo-electron microscopy.
Computer-based methods have emerged as an attractive alternative, but several of these approaches are constrained by the scarcity of RNA structural data in the Protein Data Bank.
While a growing number of methods based on Deep Learning have emerged, most are highly dependent on explicit evolutionary sequence information derived from multiple sequence alignments (MSA) or implicitly make use of homologous information learned by biological language models.
Tarafder and associate professor Debswapna Bhattacharya therefore developed RNAbpFlow, a sequence- and base pair-conditioned all-atom RNA 3D structure generation method based on SE(3)-equivariant flow matching model.
Doctoral student Sumi Tarafder (left) and Associate Professor Debswapna Bhattacharya explain a new AI method that rivals Google in decoding RNA, an approach that could help discover new treatments for disease [Tonia Moxley / Virginia Tech]
RNAbpFlow incorporates conditions on the nucleotide sequence and base-pairing information from three complementary base pair annotation methods to comprehensively capture canonical and noncanonical interactions.
By incorporating a nucleobase center representation that enables the optimization of angles of all rotatable bonds of nucleobases, it directly outputs all-atom RNA structures in an end-to-end fashion.
This bypasses the need for a post-hoc geometry optimization module, which is impractical in the context of large-scale sample generation.
Base pair-centric auxiliary-loss functions maximize the realization of canonical and noncanonical base-pairing interactions. This enables efficient generation of all-atom RNA conformational ensembles while explicitly modeling nucleobase orientation and flexibility.
Experimental results demonstrated that the introduction of base-pairing conditioning led to improved performance and accuracy connected to the quality of the base pairs.
In blind testing, RNAbpFlow produced a correct overall structure for 12 of 14 RNA targets, compared with eight out of 14 for AlphaFold 3, from Google DeepMind.
“We wanted to keep it simple and predict the structure from scratch, using just the sequence and the base pairs,” Tarafder said.
“The model starts from complete noise and, guided by those base pairs, folds into the right 3D shape.
“That’s the beauty of flow matching, and we can generate as many structures as you want, which lets us capture how the molecule actually moves.”
<![CDATA[Track latest neuropsychiatry breakthroughs: phase 3 narcolepsy study launches, new depression and PTSD therapies advance, and FDA approvals reshape care.]]>
Researchers have identified a distinct set of anti-lipid antibodies that could improve the early diagnosis of Lyme disease while also helping distinguish patients who develop persistent symptoms after treatment from those who recover fully.
The study, published in Infection and Immunity, found that antibodies against specific phospholipids appear before conventional Lyme disease antibodies in some patients and persist in a subset of individuals with post-treatment Lyme disease (PTLD). The findings suggest these immune markers could eventually complement existing diagnostic tests and provide new clues about the biology underlying chronic symptoms.
Lyme disease, caused by the spirochete Borrelia burgdorferi, is the most common vector-borne infection in North America and Europe. Although most patients respond well to a two- to three-week course of antibiotics, an estimated 10% to 20% continue to experience fatigue, pain, cognitive impairment, and other nonspecific symptoms long after treatment. The biological basis for these persistent symptoms remains poorly understood, and clinicians currently lack objective biomarkers to identify affected patients.
Current diagnostic testing also has significant limitations. Standard two-tier serologic testing relies on antibodies directed against Borrelia proteins, but these antibodies often do not appear until several weeks after infection and can remain detectable long after the bacteria have been eliminated. As a result, existing tests have limited sensitivity during early infection and cannot reliably distinguish active infection from previous exposure or persistent post-treatment illness.
The new study builds on earlier work showing that B. burgdorferi scavenges lipids from its human host and incorporates them into its outer membrane. The researchers hypothesized that this unusual biology could trigger immune responses against host lipids that might serve as biomarkers of disease activity.
To test that idea, investigators analyzed serum samples from patients with acute Lyme disease and PTLD collected from two independent biobanks. Together, the cross-sectional and longitudinal cohorts allowed researchers to follow antibody responses from the day of diagnosis through one year after treatment.
Among numerous lipid targets examined, only three antiphospholipid antibodies were consistently elevated following infection. Two antibodies—anti-phosphatidic acid (αPA) and anti-phosphatidylserine (αPS)—were significantly elevated at diagnosis, including in patients with erythema migrans before they had seroconverted on conventional Lyme disease testing.
Longitudinal analyses showed that antibody levels followed distinct patterns over time. Both αPA and αPS peaked approximately three to six months after diagnosis before declining in most patients. However, αPS remained persistently elevated in a subset of individuals with PTLD, distinguishing them from healthy controls and from patients with autoimmune and chronic illnesses that often resemble post-treatment Lyme disease, including systemic lupus erythematosus, multiple sclerosis, fibromyalgia, long COVID, and chronic fatigue syndrome.
The researchers propose that persistent αPS elevations may reflect an abnormal immune response rather than ongoing infection. While the precise mechanism remains unknown, they suggest that dysregulated activation of innate-like B cells or continued exposure to phosphatidylserine antigens could sustain antibody production in susceptible individuals.
Importantly, the authors note that whether these antibodies actively contribute to disease or simply mark immune dysfunction remains uncertain. “The presence of autoantibodies does not always drive autoimmune disease,” the authors write, emphasizing that further mechanistic studies are needed.
The investigators also draw parallels with syphilis, another spirochete infection. In syphilis, lipid-directed antibody tests are routinely used alongside pathogen-specific assays to monitor disease activity and treatment response. The authors suggest a similar strategy could eventually enhance Lyme disease diagnostics.
“The addition of antilipid antibodies to these panels may improve sensitivity while retaining the more specific diagnostic antibodies,” the authors write. They note that anti-lipid antibodies could potentially function both as adjuncts for early diagnosis and as biomarkers for monitoring recovery following treatment.
The study has several limitations, including relatively modest sample sizes and the use of specimens collected from multiple biobanks with differing collection protocols. Nevertheless, the consistency of findings across independent cohorts strengthens confidence in the observations.
Ultimately, the authors conclude that “the antibodies described here may be valuable biomarkers of early or persistent disease and suggest another mechanism linking B. burgdorferi infection and pathologic autoimmunity.” Larger prospective studies will be needed to determine whether these antibodies can be incorporated into clinical practice for diagnosing Lyme disease or identifying patients at risk for persistent symptoms.
Huntington’s disease therapeutics have reached a historic milestone—the first patient has successfully received an experimental neural stem cell therapy at UCI Health. This groundbreaking dose marks the world’s first human trial of embryonic stem cell-derived neural stem cells for the devastating neurodegenerative disorder.
The treatment, performed in May at University of California Irvine (UCI) Health, represents the culmination of more than 12 years of laboratory research and eight years of clinical planning led by scientists and physicians at the University of California, Irvine. Researchers hope the treatment, known as hNSC-01, could eventually slow disease progression, protect vulnerable brain cells and potentially restore damaged neural circuits.
To date, the first participant has not reported any serious adverse effects, according to the clinical team. A second patient is expected to receive the therapy in July.
Leslie M. Thompson, PhD, Donald Bren Professor of psychiatry and human behavior, as well as neurobiology and behavior, at the University of California, Irvine [UC Irvine]
“This clinical trial highlights the important role that an interdisciplinary academic and clinical team, together with the HD families, plays in advancing medicine,” Leslie M. Thompson, PhD, clinical trial sponsor as well as the Donald Bren Professor of psychiatry and human behavior UC Irvine, told Inside Precision Medicine. “We are grateful to our patients and their incredible families for their bravery to provide hope for others with very few options.”
hNSC-01
Huntington’s disease, caused by a mutation in the huntingtin gene, destroys brain cells, causing involuntary movements, cognitive decline, and psychiatric symptoms that begin between 35 and 50 and worsen over time. Without a cure, the fatal disorder burdens patients and families emotionally, physically, and financially, often requiring daily and long-term care.
Current treatments for Huntington’s disease primarily focus on managing symptoms rather than altering the underlying disease process. Drugs such as tetrabenazine and deutetrabenazine can reduce involuntary movements known as chorea, while antidepressants, antipsychotics and mood stabilizers help address psychiatric symptoms. Physical therapy, speech therapy and occupational therapy can also improve quality of life. However, none of these approaches has been shown to slow or stop the progressive loss of neurons that drives the disease.
Over the past decade, researchers have pursued several experimental disease-modifying strategies. Among the most advanced are gene-targeting therapies designed to reduce production of the mutant huntingtin protein. These include antisense oligonucleotides (ASOs), which are delivered through repeated spinal injections, as well as RNA-targeting and gene-editing approaches intended to suppress or correct the faulty gene. While these strategies directly target the genetic cause of Huntington’s disease, clinical results have been mixed, and questions remain about long-term effectiveness, safety and the need for lifelong treatment.
The hNSC-01 neural stem cell therapy being tested at UCI Health takes a different approach. Rather than targeting the mutant gene itself, the therapy aims to protect vulnerable neurons, replace lost cells, rebuild damaged neural circuits and provide supportive factors that promote brain health.
The UCI researchers believe stem cell-based therapies may offer a new approach by addressing multiple aspects of the disease simultaneously. The experimental treatment, hNSC-01, consists of pluripotent neural stem cells derived from embryonic stem cells and manufactured through the UC Davis Good Manufacturing Practice facility.
Preclinical studies in animal models suggested the cells could perform several functions relevant to Huntington’s disease, including protecting existing neurons, replacing cells that have been lost, rebuilding damaged neural networks and releasing beneficial proteins such as brain-derived neurotrophic factor (BDNF). The cells were also shown to reduce harmful protein accumulations associated with neurodegeneration and demonstrated long-term safety in mice.
Unlike conventional drug therapies, the stem cells are delivered directly into the brain. During the approximately six-hour procedure, performed under general anesthesia, patients lie face down within an MRI scanner while neurosurgeons use a specialized stereotactic navigation and delivery system to implant the cells into the striatum, a deep brain structure heavily affected by Huntington’s disease.
The striatum plays a central role in motor control, decision-making, motivation and learning. Degeneration of this region contributes significantly to the hallmark symptoms of the disorder. The first intervention was delivered by UCI Health neurosurgeon Jefferson W. Chen, MD, and a multidisciplinary surgical team.
Tracking treatment impact
As a Phase Ib/IIa study, the trial’s primary objective is to evaluate safety. However, researchers will also track biomarkers and clinical indicators that may provide early clues about whether the treatment is affecting disease progression.
When asked which biomarkers would help identify how the therapy is working in patients, Thompson emphasized that current measurements are focused more on assessing treatment impact than revealing biological mechanisms. “We will be including HD relevant clinical endpoints and biomarkers, including NfL in plasma and NfL and PENK in CSF; however, these are geared to understanding whether the treatment is having a benefit to these outcome measures versus informing the mechanism of action,” Thompson said.
One of the most important early indicators will be whether disease-related biomarkers remain stable rather than continuing their expected decline. “The earliest sign first and foremost is safety in this initial trial,” Thompson said. “Initial signs that the therapy could be meaningfully altering disease progression would be if the blood-based or CSF-based biomarkers do not show progression.”
Reaching the point of treating the first patient required overcoming a series of scientific, manufacturing and logistical hurdles. According to Thompson, selecting the optimal cell line was among the most significant challenges, testing multiple cell lines in vitro and in vivo.
Researchers also had to establish quality-control standards for the final therapeutic product and create Good Manufacturing Practice cell banks following extensive testing in Huntington’s disease mouse models. The COVID-19 pandemic introduced additional delays. “Disruptions caused by COVID-19, in particular the safety and tumorigenicity studies, delayed the timeline,” Thompson explained.
Another major undertaking involved creating the clinical infrastructure necessary for a first-of-its-kind procedure. Thompson said that it’s not really a challenge, but getting the overall procedural pipeline in place is the first study of this kind at the UCI Health–Irvine hospital in the MRI suite.
Despite the complexity of the project, Thompson said interactions with regulators proceeded smoothly. “We actually had a very good experience in terms of regulatory activities. A very helpful pre-pre-IND, pre-IND and relevant feedback from the FDA on the clinical trial.”
Scalability and competitive landscape
Whether hNSC-01 will ultimately compete with or complement emerging gene-targeting therapies remains unclear. Gene-silencing approaches may be easier to distribute because they do not require brain surgery, but repeated administrations over many years could result in substantial cumulative costs. In contrast, hNSC-01 involves a specialized MRI-guided neurosurgical procedure that may initially be limited to major medical centers, but it is designed as a one-time treatment whose long-term costs could compare favorably with chronic therapies if benefits prove durable.
Thompson believes the infrastructure requirements may be less of a barrier than many assume. “Yes, major medical centers can eventually offer it, and several medical centers are now using this system for other indications,” she said. “The other aspect is this would be a one-time administration so an individual could even travel to a medical center that offers the procedure.”
The REGEN4HD trial plans to enroll 21 adults aged 18 to 65 with early-stage Huntington’s disease. Twelve participants will be included in a Phase Ib dose-escalation cohort, while nine additional participants will be enrolled in a Phase IIa expansion group. The study is funded through a $12 million grant from the California Institute for Regenerative Medicine and coordinated through the UC Irvine Alpha Clinic, one of nine state-supported regenerative medicine clinical research centers.
Even if the therapy proves safe and beneficial, researchers caution that it remains unclear whether stem cell transplantation alone will be sufficient to combat Huntington’s disease over the long term. “At this point we do not know whether this will be sufficient alone or will need to be delivered with other disease-modifying therapies,” said Thompson. “For example, ones that specifically target an HD mechanism such as somatic repeat instability,” Thompson said. “However, these cells also have the potential to exert therapeutic effects directly while serving as vehicles for the delivery of additional interventions.”
For families affected by Huntington’s disease, the first successful treatment in the REGEN4HD trial represents more than a scientific milestone. It marks the beginning of a new chapter in regenerative medicine—one that researchers hope could eventually transform the outlook for a disease that has long remained untreatable.
Facial paralysis is a disabling condition with severe functional and aesthetic consequences. Facial paralysis affects approximately 1.8% of individuals over their lifetime, with approximately 30% of affected patients developing persistent deficits; among these, patients with permanent flaccid paralysis and severe facial asymmetry do not resolve with pharmacological treatment and require surgical intervention. It is specifically this surgically relevant subgroup that represents the target population of the SMILE framework. The SMILE framework (bypaSs of a facial nerve lesion through intra-body biocoMpatIbLE communication technologies) validates the feasibility of the communication infrastructure required to establish a functional neural bypass link between the healthy side and a surgically reinnervated contralateral side of the face. This work presents a preliminary interdisciplinary experimental and engineering approach underlying the SMILE framework, combining neurophysiological validation in 15 adult Wistar rats with the design of ultra-low-power intra-body communication links based on galvanic coupling (GC) and ultrasound (US). Microsurgical cuff electrodes were implanted around the buccal branch of the healthy facial nerve to record odor-evoked motor outputs. ENG signals recorded from the intact buccal branch of the facial nerve on one side were transmitted to the contralateral side, across the animal’s facehead. Engineering evaluations demonstrated robust transmission capabilities, with the GC link achieving a mean equivalent SNR of 18.2 ± 0.6 dB and a mean normalized cross-correlation of r = 0.72 ± 0.09 between transmitted and reconstructed ENG signals, with MSE on the order of 10−2. The US link achieved an equivalent SNR around 12 dB with MSE around 5 · 10−2, supporting the feasibility of intra-body neural signal relay through biological tissues.
Apple. Anthropic. Disney Research. Google. Meta. Microsoft. NVIDIA. OpenAI. Few places outside Silicon Valley can claim R&D hubs from all of these companies. Fewer still are concentrated in a city of just over 400,000 people—roughly half the size of San Francisco.
Over the past two decades, however, many of the world’s most influential technology companies have established R&D operations in and around Zurich, Switzerland. What began with Google’s decision to build its largest R&D hub outside the United States has evolved into one of the world’s most concentrated centers for AI research, talent, and commercialization, in certain areas at a higher density than Silicon Valley.
The question is why so many technology leaders keep choosing the same place to build and scale.
Located at the center of Europe, Greater Zurich Area, a region spanning the cantons of Glarus, Graubünden, Schaffhausen, Schwyz, Solothurn, Tessin, Uri, Zug, and Zürich, the region of Winterthur, and the city of Zurich, combines access to major markets with political stability, regulatory predictability, and strong intellectual property protection. And Zurich Airport connects the region directly with key business hubs across Europe, North America, and Asia, making it an efficient base for international operations.
The country’s innovation performance reinforces this position. Switzerland has ranked first in the Global Innovation Index for more than a decade, leads the world in patents per capita, and invests over 3.3% of GDP in research and development. Earlier this year, google.org pledged a $1 million grant to the Swiss National AI Institute, a joint effort to advance AI research for the public good.
Switzerland’s venture ecosystem reflects a similar focus. Over 60% of Swiss venture capital is invested in deep tech—the highest share globally by a large margin and nearly twice the share of major economies like Germany, France, and the UK. And, according to the Swiss Deep Tech Report 2026, at $1,470 invested per capita, Switzerland commits more to deep tech per capita than any other country in Europe.
The economics of specialization
While Switzerland is one of Europe’s most expensive locations for talent and operations, salaries remain at a fraction of those in Silicon Valley. The talent pool is small by global standards. Scaling a team quickly is harder in Zurich than in London, Paris, or Amsterdam. For early-stage companies that need to hire fast and burn lean, that trade-off is real. For companies building specialized AI capabilities, however, the equation works: The objective is to assemble the right team, not the largest one.
Switzerland’s economy is built around high-value, knowledge-intensive work. Productivity is among the highest in the world, and companies concentrate on functions that depend on specialized expertise rather than large workforces. For companies developing advanced AI capabilities, cost is often weighed against factors that are harder to replicate elsewhere: direct access to leading universities and research institutions, regulatory stability, and a quality of life that helps attract and retain skilled international talent.
A high-density AI ecosystem
Within Switzerland, the Greater Zurich Area concentrates many of the ingredients required to build and deploy AI systems.
The defining characteristic of this region is density. Many of the world’s leading AI companies, research institutions, investors, and startups operate in close proximity, creating connections between talent, capital, and ideas.
For example, Google engineers teach at ETH Zurich. ETH graduates join companies such as Anthropic. Researchers launch startups, while former employees of global technology firms go on to found new ventures of their own. Investors, founders, academics, and corporate teams encounter each other repeatedly through shared networks, industry events, and professional circles. In a region of this size, collaboration often happens less through formal introductions than through proximity. While talent flows freely, it rarely leaves the ecosystem.
One indicator of the region’s maturity is its ability to convene. Events such as the Zurich AI Festival will bring together more than 6,500 guests this September 28 to October 3. With more than 35 confirmed events across AI and the arts, AI literacy, health, technology, and policy, it is designed as a platform for cross-sector exchange. Its flagship events, the AI + X Summit, AI + Environment, and the AI + Policy Summit, will bring together internationally recognized leaders alongside researchers, policymakers, venture capitalists, and entrepreneurs, convening international voices and fostering dialogue across sectors.
Research, talent, and company creation
At the center of the country’s AI capabilities are institutions such as ETH Zurich, the University of Zurich, École Polytechnique Fédérale de Lausanne (EPFL), Scuola Universitaria Professionale della Svizzera Italiana (SUPSI), and Zürcher Hochschule für Angewandte Wissenschaften (ZHAW).
ETH Zurich ranks among Europe’s leading universities for deep tech commercialization, generating more than 40 spin-offs and startups in 2025 alone, helping create some of the continent’s most valuable technology companies.
The Stanford AI Index 2026 reinforces that picture: Switzerland ranks first globally for AI researchers and inventors per capita, with 110.5 per 100,000 inhabitants—ahead of Singapore (109.5), Sweden (80.6), and the United States (64.8). And the IMD World Talent Ranking ranked Switzerland as number 1 for the 10th consecutive year, leading globally in investment, development, and talent appeal.
Engineers, researchers, and founders move frequently between universities, startups, and established technology firms, creating strong knowledge flows across organizations. That density is increasingly attracting companies from outside the region too. Even before formally announcing their Zurich office, Exa.ai received a strong pipeline of candidate applications. ‘To assemble the greatest search team in the world, you’ve got to meet people where they are,’ says Will Bryk, the company’s CEO and co-founder. ‘And many are in Greater Zurich.’
Former Google Switzerland employees alone have founded approximately 210 companies and created around 2,600 jobs over the past two decades. For a country of around nine million inhabitants, the multiplier effect is significant. Large technology firms contribute not only through direct employment, but also through the creation of new companies and the transfer of expertise.
Why the Greater Zurich Area complements Silicon Valley
For many technology companies, Switzerland is not a substitute for Silicon Valley. The two serve different functions within the AI value chain.
Silicon Valley remains unmatched in scale, venture capital, and frontier model development, but for global technology companies, an R&D presence in Switzerland has increasingly become a strategic complement: a way to access specialized talent, stay close to leading research, and build capabilities that will shape the next generation of products and services.
This is particularly relevant for companies working at the intersection of AI and the physical world. Switzerland offers direct access to leading universities, industrial partners, and sectors such as healthcare, finance, manufacturing, and robotics, where reliability, compliance, and precision are often as important as raw model performance.
Geography is strategy
Global AI leaders came to the Greater Zurich Area because the region concentrates capabilities that are often distributed across multiple locations: world-class research, specialized talent, industrial partners, capital, and pathways to deployment. Those advantages were built over decades, not years.
For companies evaluating where to build the next generation of AI products, the answer may not be another larger ecosystem. It may be one where the distance between research, talent, capital, and deployment is measured in minutes rather than hours.

![This image depicts both healthy (right) and deteriorated (left) human retinal endothelial cells, which are essential for maintaining eye sight. The deterioration is caused by low oxygen and high glucose levels, mimicking conditions found in diabetic retinopathy, the leading cause of vision loss in working-age people in the United States. [Duke University]](https://www.genengnews.com/wp-content/uploads/2026/06/Low-Res_retina-cells-treatment-300x150.jpg)